
Predicting International Box Office Success
Last week my Metis Data Science summer cohort completed and presented our second project. Unlike our first project, this was a solo effort. We were coached up on Python scraping tools Selenium and Beautiful Soup, sent out to find meaningful conclusions from movie data using linear regression.
Goal
When looking at the data readily available on websites like Box Office Mojo I noticed that one of the more interesting items found on each film’s page was its percentage of foreign box office. We tend to think of everything, including movies, in their relation to domestic success, but international revenue has been an increasing source of profits for movie studios.
I wanted to find the most relevant features for predicting the percentage of a film’s foreign box office, which could be the difference between a hit or bust for investors and studios.
The Data
I wanted to spend as much time as possible analyzing the data, so I avoided bringing together data from multiple sites.
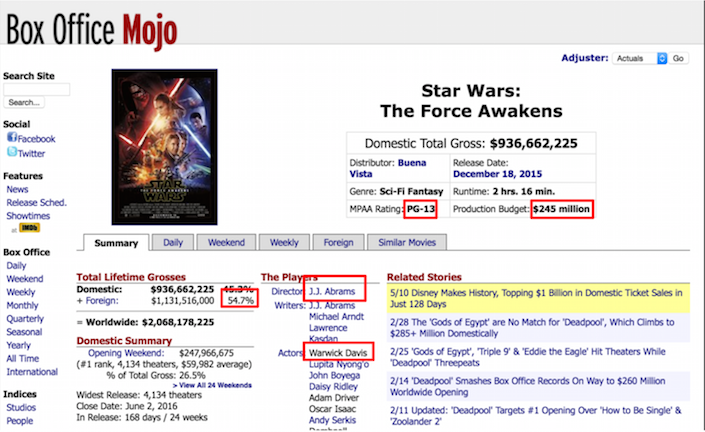
Right on a film’s Box Office Mojo main page were some potentially important data:
- Budget
- Genre
- Rating
I also saw that each film listed its top directors and actors, with links to their own Box Office Mojo web pages. This gave me an idea to add a little more than only the data from the film’s main page to the analysis: I could find out if the film’s director and lead actor have had a history of foreign box office success.
Here are the pieces of information I took from the film’s main page.
How to Measure a Director/Actor’s Foreign Success
Once I figured out how to access the director’s and actor’s movie pages, I needed to decided what measure to use to gauge their previous foreign success.
I knew that I could only use metrics from films released before the film being predicted. Films released after the date wouldn’t provide relevant data for making future predictions. Therefore I looked at only films made within the five years prior to the film predicted, and calculated the average foreign percentage for each film’s director and lead actor.
Getting an Initial View
Once I had the data I wanted for my analysis, I needed to take an initial look to see which data looked useful, and if any transformations were necessary.

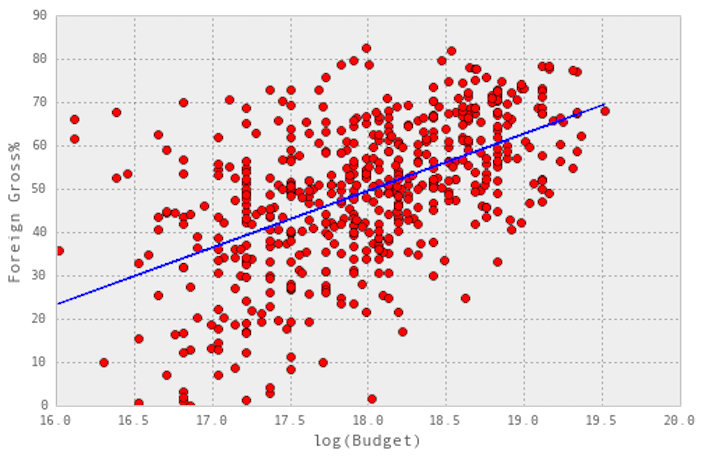
While the historical foreign success of the film’s director (center plot) and lead actor (right) looked to have a linear relationship, budget (left) took on a different shape. I did a log transformation on the budget figures, making them much more palatable for linear regression.
The categorical variables genre and rating did not measure nearly as statistically significant for predicting foreign box office percentage. The p-values for movie ratings were not significant at the 0.05 threshold, unlike the the other features.
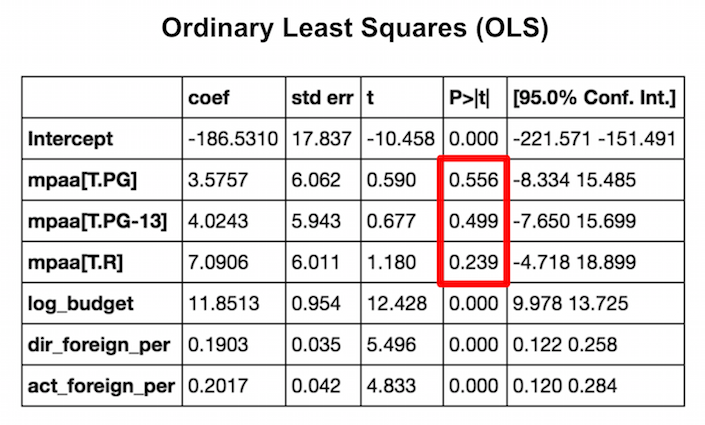
I decided to move forward only using my three most significant features: Budget, Director’s Historical Foreign Success and Lead Actor’s Historical Foreign Success.
Training, Cross-Validation & Testing
The next steps were to split the data into training and testing sets (75%-25%), and perform cross-validation on the training data for feature selection insight. Then I would apply the linear regression model derived from the training data on the testing set to gauge its accuracy on an out-of-sample data set.
I calculated the average mean squared error on five different cross-validation folds for each potential mix of features.
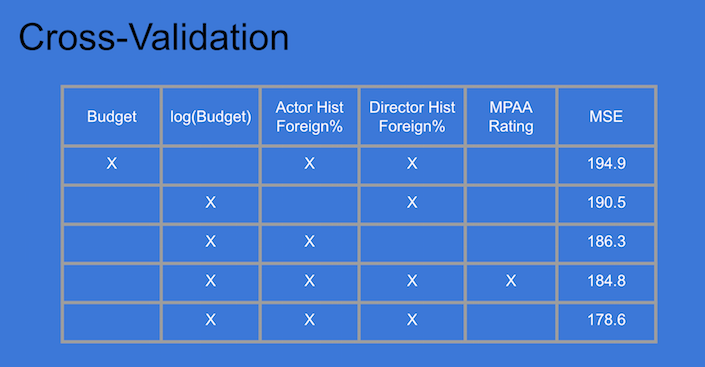
The results showed the the lowest error, and therefore most accurate model, included the three features I thought would be most significant.
Then I applied the training model on the testing set, and to my pleasant surprise, the mean squared error was slightly lower than that on the training set. The coefficient of determination, or R-squared, was also slightly lower, though not particularly strong at 0.386.
Code & Presentation
Here are links to my GitHub repository that houses my project code and presentation.